2. Materialien und Daten
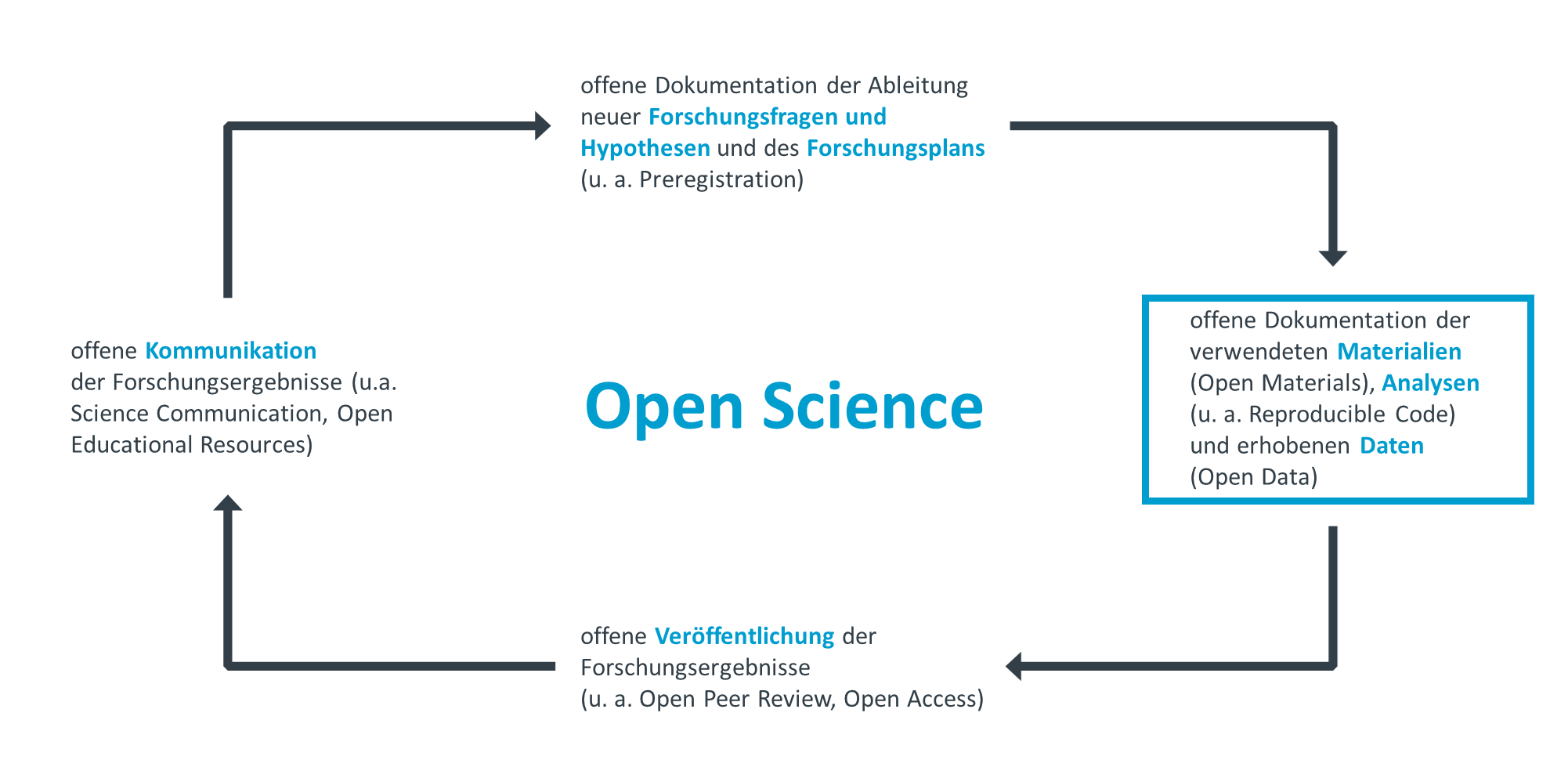
Open Materials
Öffentlich zugängliche und sauber aufbereitete Forschungsmaterialien erhöhen die Nachvollziehbarkeit von Forschung und vereinfachen Reproduktion (erneute Prüfung mit denselben Daten) und Replikation (erneute Prüfung mit neuen Daten).
Worum geht’s?
Open Materials betreffen die transparente Beschreibung, Dokumentation und öffentliche Zurverfügungstellung des methodischen Vorgehens einer Studie. Open Materials ermöglichen damit eine genaue und umfassende Kommunikation des eigenen methodischen Vorgehens, eine angemessene Interpretation der mit diesem Vorgehen erhobenen Daten und der darauf aufbauenden Ergebnisse und eine direkte Replikation des methodischen Vorgehens. Konkret beinhaltet „Open Materials”:
die Dokumentation aller verwendeten Abläufe, Gerätschaften, Materialien und erfassten Variablen
die Zurverfügungstellung dieser Dokumentation auf einem öffentlich zugänglichen Online-Repositorium
Die akkurate Beschreibung der relevanten Methoden im Paper (Vorgehen und Begründung Stichprobenziehung, Ausschluss von Versuchspersonen/Daten, alle relevanten Prozeduren und Variablen) plus Link zu der zusätzlichen öffentlichen Dokumentation (Codebook, alle Materialien)
Publikationen
Simmons, J. P., Nelson, L. D., & Simonsohn, U. (2012). A 21 word solution (October 14, 2012). Available at SSRN: https://ssrn.com/abstract=2160588 or http://dx.doi.org/10.2139/ssrn.2160588
Schönbrodt, F., Gollwitzer, M., & Abele-Brehm, A. (2017). Der Umgang mit Forschungsdaten im Fach Psychologie: Konkretisierung der DFG-Leitlinien. Psychologische Rundschau, 68, 20–35. https://doi.org/10.1026/0033-3042/a000341
Weiterführende Informationen
Disclosure templates: https://osf.io/m7f8d
Manual zum Datenmanagement und Data Sharing in der Psychologie: http://psychdata.zpid.de/downloads/PsychData-Handbuch_2013.pdf
Psych Data Metadatenformular: https://www.psychdata.de/downloads/formular_datengeber.pdf
CONSORT 2010 – Checklist: http://www.consort-statement.org/media/default/downloads/CONSORT%202010%20Checklist.pdf
ICPSR. (n.d.). Guide to social science data preparation and archiving: Phase 3: Data collection and file creation. Retrieved from http://www.icpsr.umich.edu/icpsrweb/content/deposit/guide/chapter3quant.html
Lösungen
Open Materials können auf sehr unterschiedliche Art und Weise, mit unterschiedlichsten Hilfsmitteln und in sehr unterschiedlichem Detailgrad bereitgestellt werden. Ziel sollte es jeweils sein, einen vollständigen Überblick der Methodik einer Studie zu geben (inkl. solcher Prozeduren und Variablen, die ggf. nicht in ein konkretes Paper eingeflossen sind) und hierüber eine angemessene Interpretation der Ergebnisse und eine direkte Replikation der Datenerhebung prinzipiell zu ermöglichen. Optimalerweise sollte eine direkte Verbindung mit Open Data gegeben sein, indem für jede in einem Codebook oder einer Variablenliste beschriebene Variable auch der im Datensatz verwendete Name angegeben wird.
Open Materials: KURZ UND KNAPP
Auch bei begrenzter Zeit lassen sich Open Materials Praktiken in den Forschungsablauf integrieren. Das Ergebnis der Open Materials Dokumentation könnte bspw. ein 2-3-seitiges PDF-Dokument sein, in dem die Abläufe und Instrumente knapp als Bullet-Point-Listen zusammengefasst sind, ggf. ergänzt um eine Excel-Datei, in der alle Items inkl. Wortlaut und Bereich möglicher Ausprägungen aufgeführt sind. Weitere/alternative schnell zu erstellende Materialien sind je nach Untersuchungskontext denkbar (bspw. exportierte Unipark-Codebooks im Fall von Online Surveys oder Online-Experimenten).
1. Beschreiben Sie die Abläufe, mit denen ihre Daten erzeugt wurden.
Ihre Auflistung sollte Nachnutzenden einen Überblick darüber geben, wie Sie bei Ihrem Forschungsvorhaben vorgegangen sind. Nennen Sie alle Versuchsabläufe und verwendeten Instrumente (inkl. ggf. Referenz) in der Reihenfolge der tatsächlichen Durchführung.
2. Beschreiben Sie die erfassten Variablen.
Erstellen Sie eine Liste mit allen verwendeten Variablen (inkl. Name, Bedeutung, Wortlaut, Wertebereich).
Kennzeichnen Sie eigenkreierte Items, falls vorhanden.
Nennen Sie die von Ihnen verwendeten Skalen und die Itemzuordnungen zu Skalen (inkl. ggf. notwendige Rekodierungen).
3. Laden Sie Ihre Dokumentation hoch.
Laden Sie Ihre in den Schritten 1 und 2 erstellte Dokumentation der Methoden und zusätzlich alle verwendeten Originalmaterialien (wenn lizenzrechtlich möglich) auf einem öffentlich zugänglichen Repositorium (bspw. www.osf.io) hoch.
4. Verlinken Sie die Dokumentation im Paper.
Zusätzlich zur Beschreibung der Methoden im Paper selbst sollten sie in den Text des Papers einen Link integrieren, der zu der Open Materials Dokumentation führt.
Open Materials: DETAILLIERT
Wenn möglich ist eine ausgiebigere und mit Beginn der Planung eines Forschungsprojekts angelegte Dokumentation aller Methoden zu empfehlen.
1. Erstellen Sie ein Codebuch.
Eine vollständige und nachvollziehbare Dokumentation der Methodik über ein systematisches Codebook macht nicht nur die eigene Vorgehensweise transparent und verständlich, sondern hilft auch, Fehler und Hürden früh zu entdecken und zu beseitigen. Sie ist zudem eine gute Grundlage für die Planung weiterer (Anschluss-)Studien. Um eine optimale internationale Rezeption zu ermöglichen, ist es in den meisten Fällen empfehlenswert, eine deutsche und eine englische Version des Codebooks (und aller Materialien) zur Verfügung zu stellen. Häufig empfiehlt sich eine Trennung des Codebooks in eine Dokumentation auf Studienebene und eine Dokumentation auf Variablenebene. Aber auch integrierte Lösungen sind denkbar, in denen bspw. Instruktionen zu einem Verfahren und die jeweilige Referenz direkt von der Beschreibung der mit dem Verfahren erfassten Variablen gefolgt werden. Die im Folgenden beispielhaft beschriebenen Hinweise sind nur eine von vielen möglichen Lösungen.
1.1 Dokumentation auf Studienebene
Erstellen Sie eine Datei, in der Sie Angaben zu folgenden Kategorien machen:
Beteiligte: Personen, Institutionen und ihre Rollen/Beiträge
Titel des Forschungsvorhabens
Hintergrund der Studie: Theoretischer Hintergrund, Verweise auf Hintergrundliteratur, Zielsetzung, Fragestellung etc.
Stichprobenmerkmale: Details zur Gewinnung der Stichprobe z. B. Beschreibung der Zielpopulation, Power-Analyse, Ziehungsprozedur, finale Stichprobengröße etc.)
Gewichtungsverfahren: falls relevant: Beschreibung der Prozedur zur Gewinnung von Gewichtungsfaktoren
Erhebungszeitraum
Erhebungsort
Beschreibung der Datenerhebungsprozedur: Terminierung und Ablauf der Erhebungssitzungen ggf. inkl. der Beschreibung eines standardisierten Versuchsleiter-Verhaltens, angewendete Erhebungsinstrumente (inkl. Referenzen), alle Instruktionen, Software und Hardware
Beschreibung der Maßnahmen zur Sicherung der Datenqualität: Pilotstudien, Konsistenzprüfungen etc.
Angaben zu nachgenutzten Sekundärdaten
Fördermittel, Förderkennzeichen
Schlagworte zur inhaltlichen und methodischen Charakterisierung der Studie: z. B. Klinische Studie, Querschnittsstudie
Aus der Studie hervorgegangene Datensätze: Beschreibung der Datensätze und Verweis auf die entsprechenden Datensatz-Dateien
Aus der Studie hervorgegangene Publikationen
Sonstige für die Dateninterpretation wichtige Dokumente: Kurzbeschreibung und Verweis auf die entsprechenden Dateien
1.2 Dokumentation auf Variablenebene
Ein ausführliches syntaxkonformes Codebuch auf Variablenebene kann bspw. folgende Bestandteile aufweisen und in folgender Syntax notiert sein:
<Variablenname> (1) <Variablenbeschreibung> (1) "<Variablenitem>" (1) {<Wertemenge>} (1) {<Fehlermenge>} (1) <Wert> "<Wertelabel>" (1 oder mehr) <Fehlender Wert> "<Label fehlender Wert>" (1 oder mehr)Ein Beispiel für eine Variable könnte so aussehen:
FAM_ZU Zufriedenheit mit der Familie (Filterfrage) "Wie zufrieden sind Sie im Augenblick mit Ihrer Familie?" {1;2;3;4} {97;98;99} 1 "nicht zufrieden" 2 "" 3 "" 4 "sehr zufrieden" 97 "fehlender Wert (Vp verweigert)" 98 "fehlender Wert (Vp weiß es nicht)" 99 "fehlender Wert (Frage nicht zutreffend)"Alternative Lösungen bestehen darin, über Tabellen (in Excel oder Word) zu arbeiten, wobei jede Variable in einer Zeile und jeder Aspekt der Variablendokumentation (Name in Datensatz, Beschreibung, Wortlaut, Skala, Wertebereich, fehlende Werte) in einer Spalte repräsentiert ist.
Falls mehrere Variablen zu einer Skala / einem Variablenblock gehören, ist es sinnvoll, diese Zugehörigkeit im Codebook kenntlich zu machen und zusätzliche Informationen zur Verrechnung und Aggregation der Variablen (ggf. inkl. nötige Rekodierungen) zu geben.
2. Stellen Sie Ihre verwendeten Materialien bereit
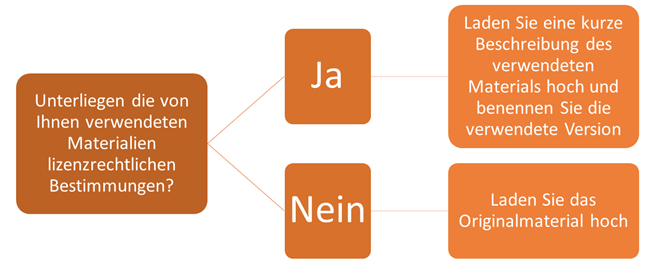
3. Daten hochladen
Laden Sie schließlich alle gesammelten Dokumente (Codebook, alle Materialien) auf einem öffentlichen Repositorium hoch (bspw. www.osf.io).
4. Dokumentation im Paper selbst
Die 21-word solution (Simmons et al., 2012) bietet eine etablierte und ökonomische Möglichkeit, die ohne großen Aufwand in jeden Methodenteil eines Manuskripts integriert werden kann (ggf. so adaptiert, dass sie korrekt ist).
“We report how we determined our sample size, all data exclusions (if any), all manipulations, and all measures in the study.”
Benannte Informationen können entweder im Manuskript selbst, oder aber in den meisten Fällen zusätzlich über die bereitgestellten öffentlich zugänglichen Online-Materialien (siehe 3. Codebook, alle Materialien) gegeben werden, um die Richtigkeit der Aussage zu garantieren. In den meisten Fällen ist es zweckmäßig, alle für ein Paper relevanten Prozeduren und Variablen detailliert im Paper selbst zu beschreiben und zusätzliche Informationen sowie nicht verwendete Prozeduren und Variablen, sowie Details und Hintergrundinformationen über das Online-Material zur Verfügung zu stellen (über einen Link im Paper; bspw. zu Beginn des Methodenteils). Neben den Abläufen und Variablen sollte im Methodenteil eines Papers in jedem Fall auch das Vorgehen der Stichprobenziehung und alle ggf. vorgenommenen Ausschlüsse von Versuchspersonen oder einzelner Daten von Versuchspersonen beschrieben und begründet werden (möglichst inkl. Power-Analyse auf der Basis konservativ geschätzter relevanter Effektstärken).
FAQ
Unter welchen Bedingungen bekommt meine Publikation den „Open materials” Stempel?
Das Journal, in dem das Paper erscheint, bietet diese Möglichkeit an.
Im Paper wird ein dauerhafter Link zu den Materialien gegeben, die in einem öffentlichen Open-Access Repositorium abgelegt sind. Die Materialien müssen einen “persistent identifier” (z. B. DOI über ein öffentliches OSF-Projekt oder ein Zenodo-Projekt) haben und in einem zeitgestempelten, unveränderlichen und permanenten Format bereitgestellt sein.
Infrastruktur, Ausrüstung, biologische Materialien oder andere Bestandteile, die nicht digital geteilt werden können, sind in ausreichender Detailliertheit beschrieben, sodass unabhängige Forschende in der Lage sind, das Verfahren zu reproduzieren.
Es werden ausreichende Erklärungen gegeben, so dass ein unabhängiger Forscher dazu in der Lage ist zu verstehen, wie die Materialien mit der berichteten Methodik in Verbindung stehen.
Typischerweise gelten seitens der Zeitschriften folgende Bedingungen:
- Provide the URL, doi, or other permanent path for accessing the materials in a public, open-access repository:
- Confirm that there is sufficient information for an independent researcher to reproduce all of the reported methodology.
Warum sollte ich überhaupt Materialien so aufwändig dokumentieren und bereitstellen?
sichert das Wissen um das tatsächliche methodische Vorgehen bei einer Studie
erleichtert die Vorbereitung ähnlicher Studien / von Folgestudien
ermöglicht eine adäquate Beurteilung der Ergebnisse einer Studie und der Auswahl der in die Analysen eingeflossenen Variablen
ermöglicht das Durchführen von adäquaten Replikationen des originalen Forschungsbefundes
gewährleistet die langfristige Nachprüfbarkeit von wissenschaftlichen Ergebnissen, auch im Hinblick darauf, dass erhobene Daten zukünftig mit anderen und ggf. besseren Methoden analysiert werden können, als dies zum Zeitpunkt der Erhebung der Fall war
erleichtert die Kommunikation und Zusammenarbeit mit anderen Forschern
Codebook
Daten können nur wiederverwendet werden, wenn Variablen und Werte klar in einem öffentlich verfügbaren Codebook beschrieben sind.
Worum geht’s?
In einem Codebook sind alle Variablen eines Datensatzes und die jeweiligen möglichen Werte beschrieben. Das ermöglicht die Weiterverwendung der Daten durch Dritte (beispielsweise Kollegen, Nachfolgen, oder andere Forschende). Je nach Programm gibt es die Möglichkeit, Variablen- und Werte-Labels zu ergänzen (z. B. in .sav Daten via SPSS1). Alternativ kann eine Übersichtstabelle erstellt werden.
| Variablenname | Bedeutung | Mögliche Werte |
|---|---|---|
| id | Versuchspersonennummer | fortlaufende ganze Zahl |
| v1 | Selbst berichtetes Geschlecht | 1 = weiblich, 2 = männlich, 3 = divers, 4 = möchte ich nicht sagen, -1 = fehlend |
| age | Selbst berichtetes Alter in Jahren | ganze Zahl |
Open Data
Offene und strukturierte Daten dienen als Grundlage zur Prüfung von wissenschaftlichen Berichten, erleichtern Replikationen und dienen als Grundlage für zukünftige darauf aufbauende Forschung.
Worum geht’s?
Open Data oder offene Daten sind Daten, die von allen frei benutzt, weiterverwendet und geteilt werden können - die einzige Einschränkung betrifft je nach Lizenz die Verpflichtung zur Nennung des Urhebers/der Urheberin[1]. Einen weiteren Schritt stellen FAIRe Daten dar. FAIR steht dabei für:
Findable: Daten sollten auffindbar sein (z. B. über Meta-Daten mittels Suchmaschinen)
Accessible: Daten können öffentlich und ohne Kosten geöffnet werden
Interoperable: Daten können mittels verschiedener Programme oder Betriebssysteme gelesen werden
Reusable: Daten entsprechen den Standards des Bereiches, aus dem sie stammen
Publikationen
Hartig, K. & Soßna, V. (2016). Forschungsdatenmanagement in DFG-Anträgen: Was kann, was soll, was muss beschrieben werden? Institutionelles Repositorium der Leibniz Universität Hannover. http://dx.doi.org/10.15488/262
Poline, J. B., Breeze, J. L., Ghosh, S. S., Gorgolewski, K., Halchenko, Y. O., Hanke, M., & Ashburner, J. (2012). Data sharing in neuroimaging research. Frontiers in neuroinformatics, 6, 9. https://doi.org/10.3389/fninf.2012.00009
Schönbrodt, F., Gollwitzer, M. & Abele-Brehm, A. (2017). Der Umgang mit Forschungsdaten im Fach Psychologie: Konkretisierung der DFG-Leitlinien. Psychologische Rundschau, 68, 20–35. https://doi.org/10.1026/0033-3042/a000341
Spindler, G., & Hillegeist, T. (2011). Rechtliche Probleme der elektronischen Langzeitarchivierung von Forschungsdaten. In S. Büttner, H.-C. Hobohm & L. Müller (Hrsg.), Handbuch Forschungsdatenmanagement (S. 63-69). Bad Honnef: Bock und Herchen Verlag. Online verfügbar unter https://univerlag.uni-goettingen.de/bitstream/handle/3/isbn-978-3-86395-066-8/GSI8_Hillegeist.pdf?sequence=1&isAllowed=y
Stodden, V. (2011). Trust your science? Open your data and code. Amstat News, 21-22. Online verfügbar unter https://stodden.net/papers/TrustYourScience-STODDEN.pdf
Weiterführenden Informationen
FAIR Prinzipien: https://www.go-fair.org/fair-principles/
Data Wiz - Ein Assistenzsystem für Forschungsdatenmanagement: https://datawiz.zpid.de/
Infos der zu Datenmanagementplänen: http://www.forschungsdaten.org/index.php/Data_Management_Pl%C3%A4ne
Infos über Repositorien: http://www.forschungsdaten.org/index.php/Repositorium und https://open-access.net/informationen-zu-open-access/repositorien/
Open Source Software für das Datenmanagement: https://www.datalad.org
Datenbank mit Datenrepositorien: re3data.org
Daten über die Uni Münster publizieren: https://www.uni-muenster.de/Publizieren/veroeffentlichung/forschungsdaten/
FAIR Aware Tool (Wissenstest zu FAIR): https://fairaware.dans.knaw.nl
Workshops und Vorträge
- Rechtliche Rahmenbedingungen bei der Anonymisierung von Daten: https://osf.io/4e8bn/
Data Wiz ‑ Assistenzsystem für Forschungsdatenmanagement
Das Leibniz-Zentrum für Psychologische Information und Dokumentation (ZPID) ist gerade dabei, ein Assistenzsystem für das Management psychologischer Forschungsdaten mit dem Namen Data Wiz zu entwickeln (https://datawizkb.leibniz-psychology.org). Data Wiz soll bei der systematischen Dokumentation aller Abläufe und Maße helfen. Die so systematisch gesicherten und dokumentierten Materialien können dann über ein Repositorium wie OSF zur Verfügung gestellt werden. Das Assistenzsystem befindet sich momentan in der Testphase.
Das ZPID richtet sich momentan strategisch generell neu aus als Universalinfrastruktureinrichtung im Sinne eines Open Science Instituts. Hierbei ist mittelfristig geplant, in ähnlicher Weise wie das OSF verschiedene Open Science Angebote der Projektplanung, -registrierung, -dokumentation, -durchführung, -archivierung und -veröffentlichung zu integrieren (siehe http://leibniz-psychology.org/).
Reproduzierbarkeit
Analysen sollten sich über die Zeit, mit verschiedenen Computer oder Programm-Versionen, und von verschiedenen Forschenden nachrechnen lassen und dieselben Ergebnisse produzieren.
Worum geht’s?
Reproducible Codes meint die Dokumentation und öffentliche Zurverfügungstellung der Codes, die aus den Daten eines Projekts (optimalerweise den Rohdaten) die in einem Paper berichteten Ergebnisse produzieren. Reproducible Codes ermöglichen damit eine genaue und umfassende Kommunikation der eigenen Analysen, ein exaktes Nachvollziehen und eine angemessene Interpretation dieser Analysen und der darauf aufbauenden Ergebnisse und eine direkte Replikation des analytischen Vorgehens.
Konkret beinhaltet „Reproducible Codes”:
die Dokumentation aller Datenaufbereitungen und statistischen Analysen in einer oder mehreren verständlich kommentierten Syntax-Datei(en)
die Zurverfügungstellung dieser Dateien auf einem öffentlich zugänglichen Online-Repositorium
Die Verlinkung zu diesen Dateien im Paper
Publikationen
Nüst, D., & Eglen, S. J. (2021). CODECHECK: an Open Science initiative for the independent execution of computations underlying research articles during peer review to improve reproducibility. F1000Research, 10, 253. https://doi.org/10.12688/f1000research.51738.2
Peikert, A., & Brandmaier, A. M. (2021). A reproducible data analysis workflow with R Markdown, Git, Make, and Docker. Quantitative and Computational Methods in Behavioral Sciences, 1-27. https://doi.org/10.5964/qcmb.3763
Weiterführende Informationen
Vorträge und Workshops
- UK Data Service Workshop zu Reproduzierbarkeit: https://www.youtube.com/watch?v=RDCHTJEOV7g
Lösungen
Reproducible codes: KURZ UND KNAPP
In einigen Fällen werden die Codes der statistischen Analysen evtl. nicht optimal aufbereitet und kommentiert sein und evtl. haben Sie nicht mehr ausreichend Zeit dies nachzuholen. Um in diesem Fall trotzdem zeitnah Reproducible Codes zur Verfügung zu stellen, sollte zumindest geprüft werden, ob die Anwendung der Codes auf die Daten tatsächlich die im Paper berichteten Zahlen erzeugt. Darüber hinaus kann knapp geprüft werden, wo einfache Kommentierungen ergänzt werden können, um die Verständlichkeit der Codes zu erhöhen. Um auch in kurzer Zeit hilfreiche Codes zur Verfügung zu stellen, kann bspw. geprüft werden, ob folgende Kriterien zutreffen:
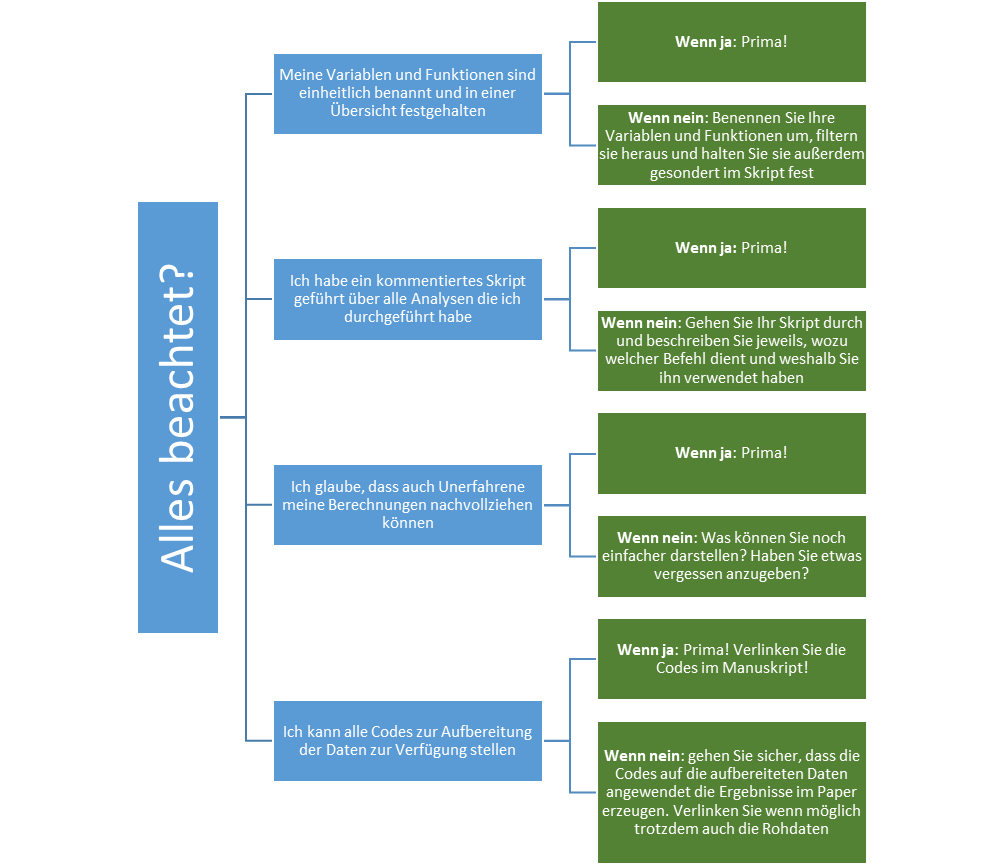
Die Codes sollten in einem öffentlichen und frei zugänglichen Online-Repositorium (bspw. www.osf.io) gespeichert werden. Im Paper (bspw. zu Beginn des Statistical Analyses- oder des Results-Teils) sollte der Link zu den Codes gegeben werden. Optimalerweise stehen dort auch die Daten als Open Data zur Verfügung, sodass die Ergebnisse eines Papers tatsächlich direkt nachvollzogen werden können und ggf. alternative Analysen durchgeführt werden können. Aber selbst wenn die Daten (bspw. aus rechtlichen Gründen oder wegen der fehlenden Möglichkeit der Anonymisierung) nicht frei zugänglich gemacht werden können, helfen Reproducible Codes auch alleine, um die statistischen Analysen (bspw. die exakte Spezifikation komplexerer Modelle) exakt nachvollziehen zu können.
Reproducible Codes: DETAILLIERT
Optimalerweise wird bereits vor der Datenerhebung geplant, ein Codebuch zu führen, die Variablen bei/nach der Datenerhebung entsprechend zu benennen und während der Datenanalyse ein hierzu passendes reproduzierbares und verständliches Skript zu führen.
Die folgenden Tipps und Richtlinien zur Erstellung eines übersichtlichen und nachvollziehbaren Codes haben beispielhaften Charakter und sind für die Statistikumgebung R formuliert.
Gliederung des Skripts
Empfohlen wird, eine einfache Gliederung im Skript einzuhalten. Diese kann im Einzelfall auch von empfohlenen Standards abweichen, sollte jedoch eine nachvollziehbare Struktur enthalten. Hier ein Beispiel:
Kommentar zum Copyright
Kommentar des Autors / der Autorin
Beschreibung der Dateien
Quell- und Zielverzeichnis
Beschreibung der Funktionen
Kommentare
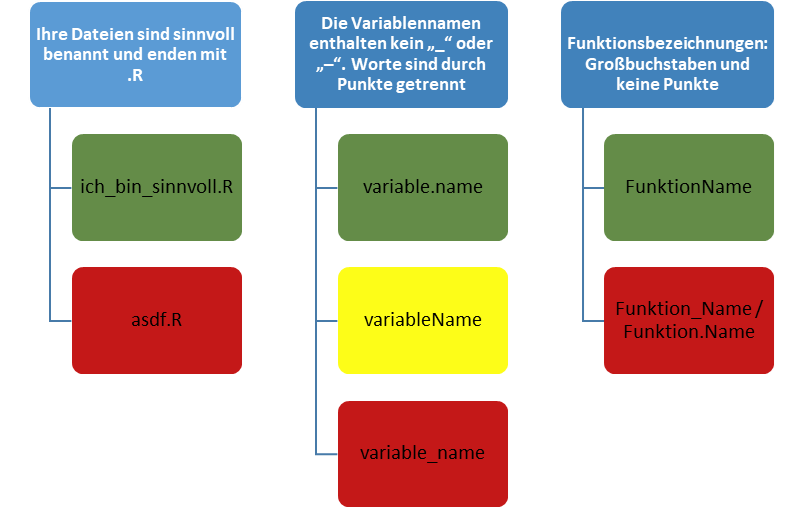
Variablen und Funktionen benennen und festhalten
Die Benennung von Variablen und Funktionen könnte nach diesem einfachen Schema erfolgen:
Richtlinien zum Kommentieren
Kommentieren Sie Ihren Code.
Ganze Kommentarzeilen, in denen kein Befehl enthalten ist, beginnen mit # und anschließendem Leerzeichen.
Kurze Kommentare, die Teile eines Befehls oder einer Funktion beschreiben, beginnen in der gleichen Zeile wie der Befehlsteil – nach zwei Leerzeichen und # .
Beispiel
# Create histogram of frequency of campaigns by pct budget spent.
pct.spent <- rchisq(50, df = 2, ncp = 0)/20
hist(pct.spent,
breaks = "scott", # method for choosing number of buckets
main = "Histogram: fraction budget spent by campaignid",
xlab = "Fraction of budget spent",
ylab = "Frequency (count of campaignids)")Richtlinien innerhalb der Syntax
Auch innerhalb der Syntax sollte einigermaßen Ordnung herrschen. Diese Punkte haben sich etabliert und werden von vielen Anwender*innen beachtet:
Nicht mehr als 80 Zeichen pro Zeile
Vor und nach Sonderzeichen in Befehlen (+, -, <, <-, usw.) je ein Leerzeichen
Kein Leerzeichen vor Kommas aber danach
tab.prior <- table(df[df$days.from.opt < 0, "campaign.id"])
total <- sum(x[, 1])
total <- sum(x[1, ])Doppeltes Leerzeichen nach einem Befehl
{ bleibt in der gleichen Zeile wie der Befehl
} endet in eigener Zeile
Für Zuweisungen wird <- benutzt, nicht =
if (is.null(ylim)) {
ylim <- c(0, 0.06)
}Komplexe Befehle sollen auf mehrere Zeilen verteilt werden.
else-Argumente befinden sich in der gleichen Zeile wie } und { .
Kein Semikolon verwenden.
if (condition) {
one or more lines
} else {
one or more lines
}Ein EINFACHES BEISPIEL
Das folgende Beispiel ist bewusst einfach gehalten und soll verdeutlichen, dass es v. a. darauf ankommt, jeden Schritt, den man in R oder einem anderen Programm tätigt, zu kommentieren, um ein nachvollziehbares Skript zu erstellen.

Lizenzen
Mittels Lizenzen schreiben Forschende, die Daten, Berichte, Skripte oder andere Forschungsmaterialien teilen, Nutzer*innen vor, unter welchen Bedingungen sie die Ressourcen weiterverwenden dürfen.
Worum geht’s?
Forschung zu veröffentlichen heißt (abgesehen bei Publikationen in kommerziellen Zeitschriften) nicht, dass Forschende alle ihre Rechte daran abtreten. Mittels Lizenzen kann bestimmt werden, wofür und in welcher Weise z. B. Daten verwendet werden dürfen. Dabei kann unter anderem bestimmt werden:
Müssen die Autor*innen zitiert werden?
Dürfen Materialien verändert werden?
Ist eine Wiederverwendung zu kommerziellen Zwecken gestattet?
Weiterführende Informationen
- Übersicht und Erklärung verschiedener Lizenzen im OSF: https://help.osf.io/article/148-licensing
Datensatz Publikationen
Daten zu einzelnen Studien lassen sich auch alleinstehend bei darauf spezialisierten Zeitschriften veröffentlichen.
Worum geht’s?
Für gewöhnlich bestehen Publikationen aus einer Frage, einer Antwort, und dazwischengeschalteten Studien mit jeweils dafür erhobenen Daten. In Fällen, bei denen eine Verwendung der Daten durch andere sinnvoll erscheint (z. B. Längsschnittstudien, Daten mit großen Stichproben, besondere Datenformate wie Liebesbriefe), bietet sich eine Datenpublikation an.
Weiterführende Informationen
Datenpublikation via Journal of Open Psychology Data und einer Manuskriptvorlage: https://openpsychologydata.metajnl.com
Datenpublikation via Earth System Science Data: https://earth-system-science-data.net
Footnotes
Mittels Open Source Software können auch solche Daten problemlos geöffnet werden.↩︎